 Print
PrintWill Goodwin is the Co-founder and Head of US Sales at Tumelo.
Introduction
Proxy voting has long been one of the most operationally demanding functions in asset management. A large institutional investor might vote on six thousand or more meetings in a single proxy season. Each meeting requires research, policy application, and a defensible rationale — produced under tight deadlines, often with limited resource. For most of the past two decades, the industry’s answer to this challenge has been outsourcing: delegating research to third-party proxy advisors whose benchmark recommendations could be applied at scale.
That model is now under significant pressure. The combination of rising expectations around fiduciary accountability, growing scrutiny of herding behaviour in institutional voting, and genuine advances in AI capability has prompted many stewardship teams to reconsider how much of the research and decision-making process should sit in-house. The recent announcement by JP Morgan that it is moving to an in-house AI platform for proxy advice reflects a broader industry shift that is likely to accelerate through 2026 and beyond.
The practical consequences of this are significant. Stewardship teams can now generate their own fully sourced outputs — “For”, “Against”, or “Refer” — within minutes of a meeting being announced, generated automatically against policies and rules they have defined themselves. Every output is auditable back to the triggered rule and the underlying sperource document, giving stewardship teams the confidence to deploy AI in a function where accountability matters. There is no manual scanning, no last-minute scramble, and no ambiguity about whether the voting decision reflects the firm’s own policies or someone else’s.
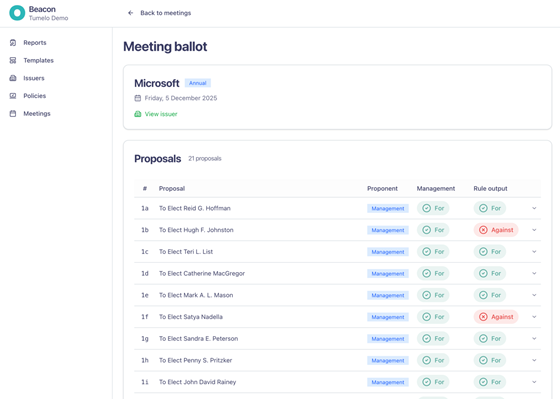
This post describes how AI can support that shift in practice — and what it takes to build a system that meets the accuracy and governance standards stewardship teams require.
The core operational problem
The challenge stewardship teams face is not a shortage of data. Proxy statements, supplemental filings, 8-Ks, 10-Ks, and company disclosures contain enormous amounts of relevant information. The challenge is turning it from unstructured to structured information, applying a firm’s own policies consistently across thousands of meetings, and doing so quickly and accurately enough that meaningful engagement is still possible.
Current workflows typically involve a combination of manual document review, third-party research, and internal analyst time. For routine votes, benchmark policy recommendations are often applied with limited customisation. For complex or contentious votes — contested elections, shareholder proposals, executive pay plans with unusual structures — deeper analysis is needed, but timelines rarely allow for it. Research that arrives late in the cycle frequently never receives human attention at all. The irony is that the meetings most likely to require careful judgement are often those where information arrives last.
This creates a specific and solvable problem for AI: not to replace the judgement that stewardship requires, but to compress the time between a meeting being announced and a stewardship team having the information it needs to make a well-reasoned decision.
How retrieval-augmented generation changes the picture
General-purpose large language models are capable of remarkable things, but they are not well-suited to the specific demands of proxy research. Asked to analyse a proxy statement, a model like ChatGPT or Claude will produce fluent, plausible-sounding output — but accuracy on long, complex documents is inconsistent. Internal benchmarking suggests accuracy rates on proxy statements of around 84% for general-purpose models, which is insufficient for a function where errors can affect votes, engagement positions, and client reports.
The more robust architecture for this domain is retrieval-augmented generation (RAG): a system in which the model is not asked to recall information from training data, but to answer questions based only on specific documents retrieved at query time. The practical implication is significant. Rather than a model guessing at the content of a filing, it retrieves the relevant sections, generates an answer based solely on that content, and provides explicit citations back to the source document. If the information does not exist in the retrieved content, the system returns a no-source-available result rather than fabricating an answer.
ProxyBeacon, Tumelo’s AI platform for proxy research, is built on this architecture — though the implementation is far from straight forward. The system integrates with third-party APIs to ingest SEC filings — DEF 14As, 10-Ks, 8-Ks, and others — for a defined universe of issuers, with filings available for research within an hour of publication. Each document is processed to extract and structure key information, converting tables, charts, and images into text, before being stored in a semantic vector database that enables meaning-based retrieval rather than simple keyword matching. When a user queries the system, ProxyBeacon retrieves the most relevant content from this corpus and passes it to a language model, which generates answers only on the basis of the retrieved material. Every output includes explicit citations to the underlying filing.
The more significant engineering challenge lies in what happens at the retrieval stage. RAG architecture performs well out of the box for precise, well-defined queries — what might be described as needle-in-a-haystack questions, where the answer exists in a specific location within a document. For broader or less well-defined questions — multi-year pay comparisons, director overboarding across multiple filings, peer group analysis — a standard semantic query returns too much irrelevant context, or “noise,” which can obscure the precise information the model needs to answer accurately. To address this, ProxyBeacon employs a multi-stage retrieval process: questions are classified before retrieval, a query plan is constructed for each, and returned results are ranked and filtered before being passed to the language model. The goal throughout is to ensure the model receives only the most relevant evidence — substantially improving accuracy relative to standard implementations, where noise in the retrieved context is one of the primary drivers of error.

Accuracy as a governance requirement
For this architecture to be useful in a stewardship context, accuracy must be measurable and auditable — not merely asserted. Building a robust evaluation framework has been one of the most significant investments in ProxyBeacon’s development.
The foundation is a benchmark dataset of question-and-answer pairs drawn from real user queries, manually reviewed, labelled, and corrected by an internal Tumelo team. Rather than relying solely on human review, a suite of LLM-based evaluation tools was then deployed to re-examine the benchmark set — surfacing any inconsistencies in the human labels themselves — and to measure model performance on an ongoing basis. These evaluators are calibrated around specific metrics, including groundedness (whether outputs are supported by the retrieved source material) and temporal awareness (whether the model correctly handles data that changes across filing periods). Crucially, the measure of correctness is end-to-end: it tests the entire RAG pipeline, from data extraction through answer generation to citation formatting, rather than any single component in isolation.
This evaluation framework is embedded directly into ProxyBeacon’s continuous integration pipeline. Lighter-weight tests run automatically whenever updates are introduced, while more expansive evaluations are triggered for larger or more fundamental changes to the model. Each time the system underperforms on a known retrieval edge case, a new test is added to prevent regression. The effect is a validation process that becomes more robust over time rather than static. The current validated accuracy rate, measured against this framework, is 99.2%.
This matters not only for the quality of individual outputs, but for the governance frameworks stewardship teams are building around AI use. Teams need to be able to demonstrate to investment committees, compliance functions, and ultimately clients that AI-assisted decisions are based on real data, traceable to source documents, and produced by a system with a measurable and independently verified error rate. A system that produces plausible-sounding output with no citation trail — and no systematic process for detecting when it is wrong — does not meet this standard.
Custom policy application at scale
One of the most valuable applications of this architecture is enabling stewardship teams to apply their own policies consistently across large voting universes, rather than relying on benchmark recommendations as a proxy for institutional views.
In practice, building and applying custom policies has historically been slow and expensive. The process typically involves significant back-and-forth between internal teams and external service providers, with limited ability to test how a policy change would have affected historical voting outcomes before it is deployed. ProxyBeacon allows users to define voting policies in plain language, apply them by market, sector, or theme, and backtest them against historical data — making policy design substantially more self-serve and the cost of iteration much lower.

Peer comparison
Peer comparison is another capability that benefits from AI-assisted research. Stewardship teams routinely need to contextualise individual company data against peer groups, both for engagement conversations and for vote decisions. ProxyBeacon allows users to define custom peer groups — rather than relying on company-reported comparisons — and produce fully sourced peer comparison reports on metrics such as CEO pay relative to total shareholder return across a defined universe.
What remains genuinely hard
It is worth being direct about the limitations of current AI systems in this domain, because the gap between what is technically possible and what meets the standard required for real stewardship decisions remains significant.
The 80/20 problem is real: getting a system to produce good outputs most of the time is achievable relatively quickly. Getting to consistent, auditable accuracy across edge cases — amended proposals, late supplemental filings, unusual pay structures, contested facts — is much harder and requires substantial ongoing investment in validation. Company disclosures are not static; proposals are amended, figures are updated, peer groups shift, and any change raises questions about what needs to be reanalysed and what conclusions are now stale. Language models themselves change over time, meaning that even a well-performing system requires continuous evaluation to detect drift.
A related principle governs where we believe AI should and should not form a view. Objective rules — “vote against if the pay increase exceeds a defined threshold” — is well-suited to AI evaluation: the criteria is measurable, the output is consistent, and the reasoning is fully auditable. Subjective rules are different in kind. “Vote for this proposal if it is material to the company” requires contextual judgement that we believe AI should not provide independently. Different models give different outputs as they have been imbued with different biases during training. In these cases, the role of the system is to surface the relevant information — voting history, support levels, proponent track record — so that the stewardship team can apply their own judgement, quickly and with full context. The point of view should always belong to the team, not the model.
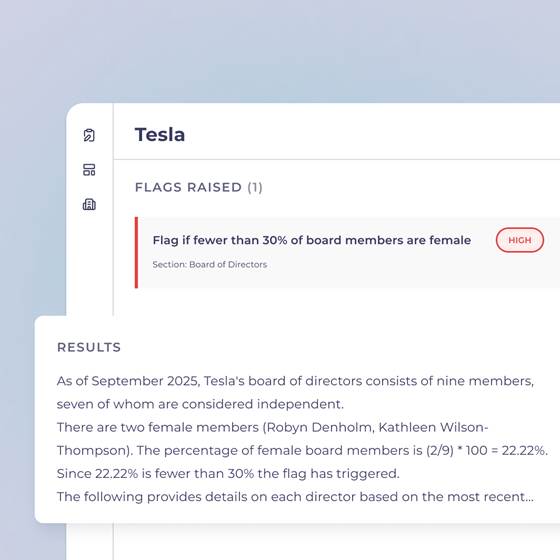
The broader trajectory
The shift towards in-house AI capability in stewardship reflects a wider reassessment of how institutional investors exercise their ownership responsibilities. As voting practices come under greater scrutiny — from regulators, from clients, from academics studying the influence of index fund voting on corporate governance outcomes — the pressure to demonstrate that voting decisions genuinely reflect a firm’s own policies and fiduciary analysis will only increase.
AI tools that are accurate, auditable, and designed around real stewardship workflows have the potential to meaningfully raise the quality of that analysis, particularly for the large proportion of meetings that currently receive limited human attention due to resource and time constraints. The question for stewardship teams is not whether AI will become embedded in proxy research workflows — that is already happening — but how to do it in a way that is rigorous, defensible, and consistent with the governance obligations that institutional stewardship carries.
